
|
| GraphvizTutorial |
UserPreferences |
| The PEAK Developers' Center | FrontPage | RecentChanges | TitleIndex | WordIndex | SiteNavigation | HelpContents |
This tutorial will show you how to use the peak.model package to create "domain model" objects for some simple applications. Our chosen subject matter for the domain model will be GraphViz, the open-source graph visualization toolkit from AT&T. The GraphViz dot tool takes input files that look like this:
digraph finite_state_machine {
rankdir=LR;
size="8,5"
orientation=land;
node [shape = doublecircle]; LR_0 LR_3 LR_4 LR_8;
node [shape = circle];
LR_0 -> LR_2 [ label = "SS(B)" ];
LR_0 -> LR_1 [ label = "SS(S)" ];
LR_1 -> LR_3 [ label = "S($end)" ];
LR_2 -> LR_6 [ label = "SS(b)" ];
LR_2 -> LR_5 [ label = "SS(a)" ];
LR_2 -> LR_4 [ label = "S(A)" ];
LR_5 -> LR_7 [ label = "S(b)" ];
LR_5 -> LR_5 [ label = "S(a)" ];
LR_6 -> LR_6 [ label = "S(b)" ];
LR_6 -> LR_5 [ label = "S(a)" ];
LR_7 -> LR_8 [ label = "S(b)" ];
LR_7 -> LR_5 [ label = "S(a)" ];
LR_8 -> LR_6 [ label = "S(b)" ];
LR_8 -> LR_5 [ label = "S(a)" ];
}
and turns them into pictures that look like this:
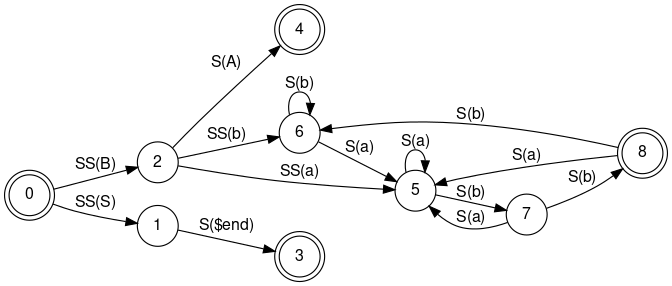
Many people have created interesting tools that use GraphViz to draw diagrams of workflow processes, clickpaths through a website, profiler call charts, even UML class diagrams. Most such programs use hardcoded templates for their .dot files and can be difficult to change because you have to know both the dot language and the application area of the software. In this tutorial, we'll develop a sophisticated framework for creating .dot files from application data that will give you flexible, object-oriented control over the visual objects to be rendered by GraphViz. We'll begin with a very simple structure using only three classes, and then, step by step, we'll show you more advanced ways to use the peak.model tools as we gradually enhance the framework's power and flexibility. Along the way, we'll share tips and techniques for ways to make the best design decisions for your own applications, in similar situations.
Before beginning any software development effort, it's important to know your scope and requirements, so let's lay out ours for this project. We want to develop a framework that makes creating GraphViz diagrams easy, for a variety of application areas. We are only interested in dot graphs, which are always directed graphs (i.e. every line has a direction to it, even if no arrows are drawn). Also, we don't need or want to be able to read or modify GraphViz files, just write them. To ensure that we have a useful framework, we'll want to develop a few simple applications that create useful output. And for our "grand finale", we'd like to be able to create a script that uses the framework to create class diagrams of the framework itself, or perhaps generate UML diagrams from an XMI file. Last, but not least, we'd like to use a minimalistic, evolutionary approach, where we "do the simplest thing that could possibly work" at each stage.
Alright, so let's get started. We're creating a domain model, so we need to know what kind of objects are in our problem domain. GraphViz graphs include the ideas of nodes and edges. An edge is directed, and connects two nodes. Nodes have names, by which they can be referenced. So here is the simplest possible PEAK domain model for such a thing:
1 from peak.api import model
2
3 class Node(model.Element):
4
5 class name(model.Attribute):
6 referencedType = model.String
7
8 class Edge(model.Element):
9
10 class fromNode(model.Attribute):
11 referencedType = Node
12
13 class toNode(model.Attribute):
14 referencedType = Node
Let's go through the above, piece by piece. Obviously, we have our Node and Edge classes to represent nodes and edges. What's not so obvious is why they inherit from model.Element, or what all those nested model.Attribute classes are for.
One of the basic contributions of the ?TransWarp framework was the idea that applications essentially consist of Services, Elements, and Features. Services are the objects which represent or compose "the application" itself, while Elements are the problem-domain objects that are managed and manipulated via the Services. Finally, Features are the objects which compose Elements: attributes, methods, relationships, even UI views or database field mappings. Features are usually contained in the body of an element's class.
The peak.model package provides base classes that support common usage patterns of Elements and Features. For example, model.Element provides support for persistence, keyword-based instance construction, and metadata about an object's features.
For features, peak.model provides the model.StructuralFeature base class, and its subclasses Attribute, Collection, Sequence, DerivedFeature, and structField. The subclasses are really just "syntactic sugar" for specifying metadata like whether the feature is derived (i.e. calculated) or stored, whether it's an ordered sequence or an unordered collection, etc. Like other Python "features" (i.e. standard methods and attributes), peak.model features are specified in the body of their containing element's class. Unlike other Python features, peak.model features are defined using a class statement. (More on the whys and hows of this later.)
In our first example domain model, we use model.Attribute because we don't need a collection or sequence for any of our object attributes. You'll notice that each attribute has a referencedType, which is set to a class that identifies the type of objects the attribute can have. This is really more informational than restrictive; by default, no type checking is done on the objects assigned to attributes or other features. (Later on, we'll see how to implement type and value checking by creating custom feature classes or by adding code to your element and datatype classes.)
The referencedType of a feature doesn't have to be the class whose instances are actually placed in the feature. It just has to be an object that implements the model.IType interface. In the case of most peak.model base classes such as model.Element, the class implements the IType interface for you. But, third-party libraries and standard Python classes aren't going to do this for you. In this case, you'll still need an object that implements the model.IType interface; it just doesn't need to be the same object as the class you're reusing.
For instance, the name attribute of the Node class in our example uses a referencedType of model.String. String comes from the peak.model.datatypes module, which defines a variety of useful basic datatypes to use for object attributes. It doesn't inherit from the Python str type, it just implements the IType interface on its behalf. The values actually placed in the Node.name attribute will be str instances, though, not model.String instances. In this way, you can easily adapt special-purpose Python classes or data types into a domain model built with peak.model.
You may be wondering by now what the point of defining features in this way is. After all, it's a lot more typing than the usual ad-hoc way of defining Python attributes. Let's play with our Node and Edge classes for a bit, so you can see some of the things that features do:
>>> A = Node(name='A')
>>> B = Node(name='B')
>>> C = Edge(fromNode=A, toNode=B)
>>> A.getName()
'A'
>>> A.setName('A!')
>>> A.name
'A!'
>>> A.unsetName()
>>> A.name
Traceback (most recent call last):
File "<pyshell#16>", line 1, in ?
A.name
File "C:\cygwin\home\pje\PEAK\src\peak\model\features.py", line 69, in __get__
return self.get(ob)
File "C:\cygwin\home\pje\PEAK\src\peak\model\features.py", line 229, in get
raise AttributeError,feature.attrName
AttributeError: name
>>> C.getToNode().getName()
'B'
>>> Node.mdl_featureNames
('name',)
>>> Edge.mdl_featureNames
('fromNode', 'toNode')
>>> Edge.mdl_features
(<class '__main__.fromNode'>, <class '__main__.toNode'>)
>>> Node(foo='bar')
Traceback (most recent call last):
File "<pyshell#27>", line 1, in ?
Node(foo='bar')
File "C:\cygwin\home\pje\PEAK\src\peak\model\elements.py", line 260, in __init__
raise TypeError(
TypeError: <class '__main__.Node'> constructor has no keyword argument foo
So where did the get() and set() methods come from? The features, of course. Feature objects are "method exporters" that generate methods from code templates and export them to their enclosing class. (You can read the reference docs of the peak.model.method_exporter module for technical details.) For simple attributes like name and fromNode, these methods aren't necessarily very useful or compelling. When we look at collection features and custom features later on, you'll see how you can use this approach to generate code for your specific application's needed methods.
Our transcript above also shows some class metadata that PEAK automatically generates for us, such as the list of each class' feature names. We'll go over these in more depth later, as we come to need them in our evolving graph framework. (For right now, if you want more detail, you can read the source code for peak.model.interfaces, specifically the IType interface.)
Finally, notice that because Node and Edge know what features they have, they can accept keyword arguments to initialize new instances with values for those features, and also validate what arguments they receive.
A domain model is more than a data model; it needs domain logic, or as it's called in the enterprise world, "business logic". Our Node and Edge classes so far only have data, not behavior. What behavior should they have?
Our goal is to be able to generate dot files, so it would be nice if nodes and edges knew how to write themselves to a dot file. But wait a second... don't we need to know which edges and nodes to write? Perhaps something is missing from our domain model. Maybe we need a Graph object that knows what nodes and edges it contains, and thus can write them to a dot file. We'll give it a writeDot() method that accepts a writable stream (file-like object) as a parameter. We'll also go back and redo our Node and Edge classes to support writeDot() methods as well:
1 class Node(model.Element):
2
3 class name(model.Attribute):
4 referencedType = model.String
5
6 def writeDot(self,stream):
7 stream.write(' %s;\n' % self.name)
8
9
10 class Edge(model.Element):
11
12 class fromNode(model.Attribute):
13 referencedType = Node
14
15 class toNode(model.Attribute):
16 referencedType = Node
17
18 def writeDot(self,stream):
19 stream.write(' %s -> %s;\n' % (self.fromNode.name, self.toNode.name))
20
21
22 class Graph(model.Element):
23
24 class name(model.Attribute):
25 referencedType = model.String
26
27 class nodes(model.Collection):
28 singularName = 'node'
29 referencedType = Node
30
31 class edges(model.Collection):
32 singularName = 'edge'
33 referencedType = Edge
34
35 def writeDot(self, stream):
36
37 stream.write('digraph %s {\n' % self.name)
38
39 for node in self.nodes:
40 node.writeDot(stream)
41
42 for edge in self.edges:
43 edge.writeDot(stream)
44
45 stream.write('}\n')
Let's try it out...
>>> A = Node(name='A')
>>> B = Node(name='B')
>>> g = Graph(
name='test',
nodes=[A,B],
edges=[Edge(fromNode=A, toNode=B)]
)
>>> import sys
>>> g.writeDot(sys.stdout)
digraph test {
A;
B;
A -> B;
}
If we had written the output to a file instead of to sys.stdout, we could have run dot over the file to produce an image like this one:
Not very impressive so far, but it's a start. In principle, we could now generate digraphs of arbitrary complexity by writing code that manipulates Node, Edge, and Graph instances. In practice, they'll be rather ugly. ![]() That's because at this point, we have no way to specify nice shapes, labels, colors, arrowheads, fonts, and so on for our nodes and edges.
That's because at this point, we have no way to specify nice shapes, labels, colors, arrowheads, fonts, and so on for our nodes and edges.
But before we start adding all that fancy stuff to the model, let's take a quick break to examine the new feature type we used, model.Collection.
XXX To Be Discussed (no particular order)
* Collection methods (add, remove, replace), singularName
* Bidirectional associations, referencedEnd, and using names for referencedType
* Label string escaping
* Label string encoding (per-font?! Object should use unicode for label and delegate encoding to its font)
* Enumerations for shapes, colors, arrows, line styles, directions, etc....
* Edges between ports
* "Record" shape support (how to handle \l, and other special escapes? What about ports?)
* Using module inheritance to mixin Node and Edge to various UML object types for drawing purposes
* Dynamically determining edge direction and arrow style from UML data
* Styles, custom feature to support "stylable" attribs like color, font, etc.
* Custom metadata, such as a class attrib that lists all a class' stylable attribs
* Constraints: node name uniqueness, nodes referenced by edges must be included in same graph
* Nested graphs and clusters; isCluster attrib, treating graph clusters as nodes
* Supporting "rank=same" (part of a style?)
* Lazily mapping from another problem domain's objects to GV domain objects
* Feature metadata including upperBound/lowerBound, isDerived, isMany, isRequired, isChangeable, implAttr, useSlot, attrName, isComposite, typeObject, sortPosn, defaultValue, etc.
* Feature methods and hooks, such as normalize(), fromString(), fromFields(), _onLink(), _onUnlink(), etc.