| Component Adaptation + Open Protocols
= The PyProtocols Package |
| Component Adaptation + Open Protocols
= The PyProtocols Package |
Double dispatch and the ``Visitor'' pattern are mechanisms for selecting a method to be executed, based on the type of two objects at the same time. To implement either pattern, both object types must have code specifically to support the pattern. Object adaptation makes this easier by requiring at most one of the objects to directly support the pattern; the other side can provide support via adaptation. This is useful both for writing new code clearly and for adapting existing code to use the pattern.
First, let's look at double dispatching. Suppose we are creating a business application GUI that supports drag-and-drop. We have various kinds of objects that can be dragged and dropped onto other objects: users, files, folders, a trash can, and a printer. When we drop a user on a file, we want to grant the user access to the file, and when we drop a file on the user, we want to email them the file. If we drop a file on a folder, it should be filed in the folder, but if we drop the folder on the file, that's an error. The classic ``double dispatch'' approach would look something like:

We've left out any of the methods that actually do anything, of course, and all of the methods for things that the objects don't do. For example, the Trashcan should have methods for droppedInTrash(), droppedOnPrinter(), etc., that display an error or beep or whatever. (Of course, in Python you can just trap the AttributeError from the missing method to do this; but we didn't show that here either.)
Every time another kind of object is added to this system, new droppedOnX
methods spring up everywhere like weeds. Now let's look at the adaptation
approach:
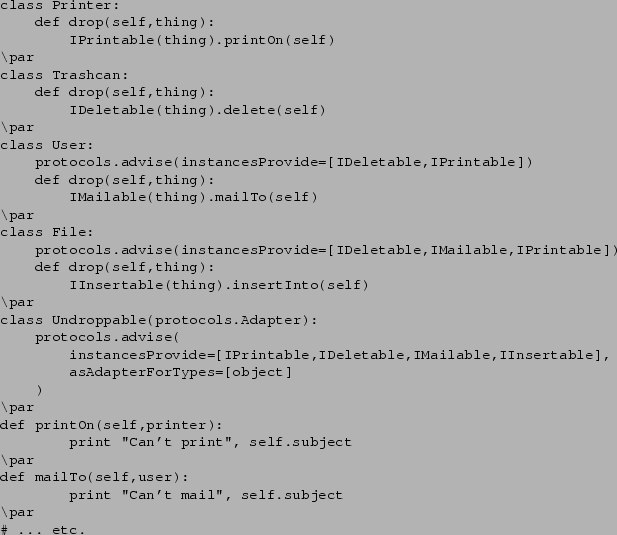
Notice how our default Undroppable adapter class implements the IPrintable, IDeletable, IMailable, and IInsertable protocols on behalf of arbitrary objects, by giving user feedback that the operation isn't possible. (This technique of using a default adapter factory that provides an empty or error-raising implementation of an interface, is an example of the null object pattern.)
Notice that the adaptation approach is much more scalable, because new methods are not required for every new droppable item. Third parties can declare adaptations between two other developers' objects, making drag and drop between them possible.
Now let's look at the ``Visitor'' pattern.
The ``Visitor'' pattern is a specialized form of double dispatch, used to apply
an algorithm to a structured collection of objects. For example, the Python
docutils tookit implements the visitor pattern to create various
kinds of output from a document node tree (much like an XML DOM). Each node has
a walk() method that accepts a ``visitor'' argument. The visitor must
provide a set of visit_X methods, where X is the name of a type of node.
The idea of the approach is that one can write new visitor types that perform
different functions. One visitor writes out HTML, another writes out LaTeX or
maybe plain ASCII text. The nodes don't care what the visitor does, they just
tell it what kind of object is being visited.
Like double dispatch, this pattern is definitely an improvement over writing large if-then-else blocks to introspect types. But it does have a few drawbacks. First, all the types must have unique names. Second, the visitor must have methods for all possible node types (or the caller must handle the absence of the methods). Third, there is no way for the methods to mimic the inheritance or interface structure of the source types. So, if there are node types like Shape and Square, you must write visit_Shape and visit_Square methods, even if you would like to treat all subtypes of Shape the same.
The object adaptation approach to this, is to define visitor(s) as adapters from
the objects being traversed, to an interface that supplies the desired behavior.
For example, one might define IHTMLWriter and ILaTeXWriter
interfaces, with writeHTML() and writeLaTeX() methods. Then, by
defining adapters from the appropriate node base types to these interfaces, the
desired behavior is achieved. Just use
IHTMLWriter(document).writeHTML(), and off you go.
This approach is far less fragile, since new node types do not require new methods in the visitors, and if the new node type specializes an existing type, the default adaptation might be reasonable. Also, the approach is non-invasive, so it can be applied to existing frameworks that don't support the visitor pattern (such as xml.dom.minidom). Further, the adapters can exercise fine-grained control over any traversal that takes place, since it is the adapter rather than the adaptee that controls the visiting order.
Last, but not least, notice that by adapting from interfaces rather than types, one can apply this pattern to multiple implementations of the interface. For example, Python has many XML DOM implementations; to the extent that two implementations provide the same interface, the adapters you write could be used with any of them, even if each pacakge has different names for their node types.
Are there any downsides to using adaptation over double-dispatch or the Visitor pattern? The total size of your program may be larger, because you'll be writing lots of adapter classes. But, your program will also be more modular, and you'll be able to group the classes in ways that make more sense for the reader. Using adaptation also may be faster or slower than not using it, depending on various implementation factors.
It's rare that the difference is significant, however. In most uses of these patterns, runtime is dominated by the useful work being done, not by the dispatching. The exception is when a structure to be visited contains many thousands of elements that need virtually no work done to them. (For example, if an XML visitor wrote text nodes out unchanged, and the input was mostly text nodes.) Under such conditions, the time taken by the dispatch mechanism (whether name-based or adapter-based) would be more visible.
The author has found, however, that in that situation, one can gain more speed by registering null adapter factories or DOES_NOT_SUPPORT for the element types in question. This shortens the adapter lookup time enough to make the adaptation overhead competitive with name-based approaches. But this only needs to be done when ``trivial'' elements dominate the structures to be processed, and performance is critical.
See Also:
| Component Adaptation + Open Protocols
= The PyProtocols Package |